
Think about how you share a Google Doc. You can add specific people to an access list or use “Anyone with the link”. The first gives some control but requires manual approvals. The second scales effortlessly but gives no control over who the link gets passed to. This captures two fundamental access models: identity-based, which grants access based on who you are, and capability-based, which grants access based on what you possess.
OAuth Was Built for Humans
OAuth 2.0 lets you grant applications access to your resources without sharing passwords. When you authorise Slack to access your Google calendar, Slack receives an OAuth access token that lets it retrieve event data on your behalf. This works because: 1) a human validates the request, 2) permissions can be broad and long-lived, or narrowly scoped at issuance, and 3) one identity represents one user.
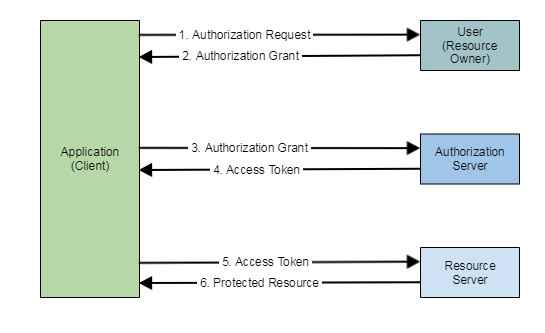
Abstract Protocol Flow, The OAuth 2.0 Authorization Framework[1]
In practice, OAuth primarily treats tokens as impersonation rather than delegated authority. ‘Sign in with Google’ grants full access within your application context. The credential represents you, not a scoped capability. This trade-off prioritises usability and session continuity over least-privilege delegation. For human sessions, implicit impersonation is acceptable. For autonomous agents, it can be catastrophic[2].
Agents need to act without constant human approval. They require fine-grained, time-limited permissions that can be safely delegated through chains of sub-agents. Multiple agents can represent one user or act for multiple users. But OAuth has no concept of delegation chains. As Microsoft’s Alex Simons writes, agents need “their own defined set of privileges - not just proxy a user’s rights”[3]. Actions must be traceable, distinguishing if an agent is acting for a user, itself, or through a chain of agents.
The fundamental limitation emerges across security boundaries. As Nicola Gallo, creator of ZTAuth* and co-chair of DIF’s Trusted AI Agents Working Group, explains, “Each web API is its own security boundary. When invoking a service that resides behind a separate security boundary, trust cannot rely on the token alone. Establishing trust requires a verifiable trust chain that validates both the token and the identity of the entity that forwarded the request.”
Most agent interactions today are not fully autonomous[4] and operate within limited scopes via protocols like MCP[5]. MCP builds on OAuth and standardises connections between AI models and other services (think USB ports for agents). This works quite well within single security boundaries, where MCP provides a common language between known agents and servers. But it doesn't address attenuated delegation, ephemeral agent lifecycles, or cross-boundary trust establishment.
“[MCP] is limited in its full scope towards authorized delegation, enabling only system communication and optionally access controls rather than broader authentication and identity management”[6].
Three Breaking Points
1/ The human-in-the-loop and ‘prompt fatigue’: 1Password’s Secure Agentic Autofill lets AI agents complete browser logins by injecting credentials without exposing them to the agent[7]. But it still requires human approval for each access. Frequent authorisation prompts can lead to “prompt fatigue”[8], where users mindlessly approve requests without scrutiny. This may work for one agent and a few resources. It breaks down completely with hundreds of autonomous agents crossing multiple security boundaries, delegating permissions to sub-agents unpredictably.
Andor Kesselman, co-founder of the Agentic Internet Workshop and co-chair of DIF’s Trusted AI Agents WG, puts it plainly: “Imagine sitting at your job, just clicking approve, approve, approve for every single OAuth request coming in from your agents. We would have created a completely dystopian world.” The paradox is the more effective your agents become, the more difficult the human-in-the-loop problem is to manage.
2/ Missing attribution: When multiple agents operate under the same account credentials, they become indistinguishable from each other both in real-time and retrospect. GitHub sees actions by “alice@company.com” but has no way to know which specific agent executed the task.
A typical organisation of 100 employees using Claude, ChatGPT, and Gemini to interact with external services might spawn an average of 10 instances per day, that’s 3000 agent instances operating daily. When something goes wrong (e.g. private internal data written to a public GitHub repository) you might see that an MCP server acted on behalf of alice@company.com’s token, but you can’t identify which agent was compromised or investigate how. Revoking one token might break multiple agents. You either keep all agents connected or shut them all down.
Andor uses the analogy of a car key. If you give your key to someone, who then gives it to someone else, who gives it to another person, and someone crashes your car, you can’t prove who did it because every access to the car used your key. This also means you remain accountable. Without distinct agent identities, delegation chains aren’t traceable, auditable, or debuggable.
3/ Agent Lifecycles: Agentic systems frequently spawn short-lived agents for specific tasks. They might exist for 15 minutes, then terminate. But OAuth assumes authorisation relationships persist over time. For ephemeral agents, you either grant overly broad access using your credentials, or create individual authorisations that require human approval, leaving stale tokens that outlive the agent.
Even longer-lived agents break OAuth’s model. Agents coordinating distributed transactions across multiple identity providers (IdPs) must have tokens that persist so the system can maintain state and handle failover. But when an agent connects to multiple IdPs with different trust relationships, it creates what Nicola calls the ‘Internet of Shared Credentials’ paradox. It also makes dynamic recovery impossible because you can’t reauthorise all transactions in real time.
OAuth’s basic model of “trust established at issuance, valid until expiration” fails for both scenarios: agents that spawn dynamically and disappear, and agents that orchestrate workflows across multiple trust domains.
Why Object Capabilities Alone Aren’t Enough
If identity-based access models don’t work for autonomous agents, what about capability-based systems? Object capabilities grant access through unforgeable tokens scoped to specific actions. They enable delegation chains, provide automatic least privilege through attenuation, and can be time-bounded. As Alan Karp writes, “Without chaining, every private in the army is saying ‘Yes sir, Mr. President.’ Without attenuation, that private ends up with permission to launch nukes.”
Much like “Anyone with the link” for Google Docs, you set capabilities upfront (e.g. ‘view’, ‘comment’, or ‘edit’) and pass them along attenuated chains to then-unknown second and third parties.
Alan’s access management use cases[9] form a key conceptual foundation for DIF’s Trusted AI Agents WG approach, and illustrate the power of capabilities through a backup scenario.
Alice tells her agent Bob: “Backup X to Y.” Bob, as a backup service provider, has broad permissions. Bob uses a copy service provided by Carol, and passes those permissions onward. But Alice changes her instruction: “Backup X to Z.” If Z is owned by Carol, she ends up overwriting her own resource. If Z belongs to someone else, Alice enables unauthorised updates to resources she doesn’t control.
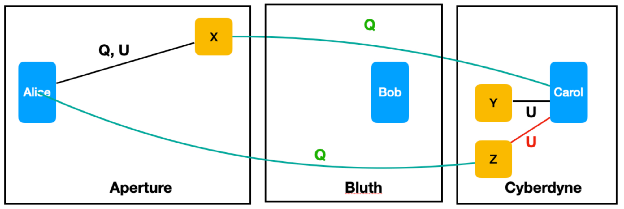
‘Transitive Access Problem’, Use Cases for Access Management
This is the ‘confused deputy vulnerability’, where a privileged service can be tricked into misusing its authority. With capabilities, Alice designates resources by delegating specific tokens: query X, update Y. Bob executes using Alice’s capabilities, not his own broad permissions. Z is safe because Alice never granted that capability.
Capabilities solve critical access control problems. But for autonomous agents operating at scale, they’re not enough on their own. Primarily because you can’t predict all capabilities upfront. And agents need capabilities to be expressed in much more limited scopes than human users. As Andor says, “you can have an agent specifically scoped to email, but humans encompass a much broader set of capabilities”.
Take Nicola’s travel example: An agent books a rental car to line up with a flight time, then the flight becomes unavailable. The agent needs to cancel that specific car booking, but you couldn’t have known which car would need cancellation when you granted capabilities. Granting “cancel any booking” upfront is too broad for an agent. But without knowing which specific agent made the booking, you can’t dynamically scope the cancellation capability to just that transaction.
”While capability-based models provide strong security guarantees and natural least privilege, they are not trivial to apply in dynamic or stateful distributed environments”, explains Nicola, “Recovery, rollback, and context rehydration require additional mechanisms beyond static capability assignment”. Even if you can apply fine-grained capabilities for security, excessive granularity becomes impractical. Too many capabilities require frequent user approvals or inter-agent exchanges. You have to balance security and operational practicality.
Dmitri Zagidulin, co-chair of DIF’s Trusted AI Agents Working Group, further explains the “patchwork problem”. Without agent identifiers, capabilities from multiple sources can be composed in unintended ways. An agent might get read access from one source and write access from another, then combine them in unintended ways, creating access patterns you never explicitly authorised.
With autonomous agents, you need to prove who they are, who spawned them, who they’re acting on behalf of, and if they have the authorisation to carry out the task they’re requesting. All in a format that the requested service can verify without “phoning home” or checking with a central authority. To do this, you need both identifiers and capabilities working together across boundaries.
Attaching Identity to Capability
“What’s becoming clear to everybody that has anything to do with AI agents is that agents and any sort of software need their own identity,” explains Dmitri, “Not just for access control, but for quality assurance.” Akin to how mobile apps have guardrails of least privilege access to other apps on your device, and registered accountability to their creators.
“When you’re interfacing with an agent, you actually do care a lot about who built the agent, where they came from, how the agent got spun up, and where it’s running,” says Andor. But as Alan notes, what matters isn’t the arbitrary identifier, it’s that the identifier enables verification of the agent’s provenance and capabilities. For example, NANDA’s first project focuses on agent discovery[10]. The system allows agents to advertise their capabilities dynamically through cryptographically verified “AgentFacts”, which declare what the agent can do, under what conditions, and with what limitations. When an agent needs specialised functionality, it queries for agents offering those services, verifies their credentials, and grants them attenuated access strictly scoped to the sub-task. This enables composable authorisation, where agents can discover and delegate to each other on the fly, rather than via centralised orchestration.
This represents a fundamental mental model shift in how we think about authorisation. Traditional identity systems operate on “authority by identity”. You prove who you are, and the system checks what you can access against a central registry. This worked for humans with relatively stable roles, particularly within organisations. Whereas agents require “authority by possession”, they prove they hold a capability token that grants specific permissions. But critically, as Nicola frames it, “Trust doesn’t come with impersonation. Trust comes from knowing who is executing the action”. You need to know who to hold accountable if something goes wrong. To establish this accountability across organisational boundaries, you need distributed and dynamic identity systems rather than centralised, static-ones.
The Case for DIDs and VCs
Decentralised Identifiers (DIDs) and Verifiable Credentials (VCs) provide the technical foundation for agents to operate across trust boundaries.
DIDs offer cryptographically-anchored identity that’s portable across platforms and organisations. Unlike email addresses or OAuth client IDs that belong to specific providers, a DID is controlled by the entity it identifies. An agent can prove its identity cryptographically without depending on a centralised authority to vouch for it every time. This portability is critical when agents need to work across multiple services that don’t have federation agreements.
VCs provide a standardised format (W3C VC Data Model, or ISO/IEC 18013-5) for expressing certificate capabilities and attestations (e.g. ZCAP-LD[11]). They’re cryptographically signed by issuers, making them tamper-evident. They can include delegation chains showing how authority flows from human to platform to agent to sub-agent. They support selective disclosure, whereby an agent can prove it has a capability without revealing more information than necessary. And crucially, they have independent lifecycles from identity, meaning capabilities can be issued and revoked separately from the agent’s core identity.
Together, they enable hierarchical identity with delegation chains, dynamic capabilities, cross-boundary trust, and complete audit trails.
Now when an agent books CAR-123, the rental service automatically issues a VC with a scoped capability: ‘“cancel”, booking ID “CAR-123”, “only by the agent that created this booking”, valid until pickup’. If the flight becomes unavailable, the agent has exactly the capability it needs without requiring human approval or having overly broad permissions.
There are of course still practical challenges with this approach. DID registration has performance implications. Revocation checking impacts latency. Key management, storage, and rotation for ephemeral agents creates new operational needs.
The alternative however, of trying to scale OAuth-based systems to billions of autonomous agents crossing organisational boundaries, is significantly more problematic. The major payment networks, Google, and Microsoft aren’t building agent identity systems because they love new standards. They’re building them because they know the current models break at multi-agent scale.
The Path Forwards
The pragmatic path forwards, as Andor explains, is to start exposing external agents with decentralised identifiers. Organisations can maintain their existing OAuth infrastructure for internal systems while giving agents portable identities for cross-boundary interactions.
Solutions like SPIFFE[12] represent a middle path. Not fully decentralised, but enabling workload identities to establish trust across organisational boundaries without requiring universal federation. SPIFFE provides cryptographically verifiable identity for workloads, creating a foundation where agents can prove ‘who is executing’ a task. However, you still need to be able to verify delegation context and trust positions. Emerging frameworks, like ZTAuth*, WIMSE[13], and others, are developing complimentary approaches that combine workload authentication with explicit delegation mechanisms.
Marketplaces provide a good business case for this. “Marketplaces are great because you can rarely capture both sides of the market,” Andor says, “You’re normally on one side or the other, so that means you have to interact with each other, and you can’t always be in your federation.” Using DIDs and VCs, agents from different platforms can establish trust and verify delegation chains without requiring pre-existing reciprocity of identification systems.
Admittedly, both Andor and Dmitri think the catalyst for change may likely be a significant security incident attributable to inadequate agent identity management, or regulatory requirements for accountability that current systems can’t satisfy. It’s better to get ahead of both.
Get Involved
DIF’s Trusted AI Agents WG is actively defining an opinionated, interoperable stack to enable trustworthy, privacy-preserving, and secure AI agents. The first work item, Agentic Authority Use Cases is focused on anchoring the important work on agents with real human led use cases, to help prioritize and discover where things break down.
Autonomous agents executing complex tasks across organisational boundaries has captured significant investment and attention, but as Andor puts it, “Identity is the first problem that needs to be solved in the agentic web to make it happen and for agents to scale”.
A huge thank you to Andor Kesselman, Dmitri Zagidulin, Nicola Gallo, and Alan Karp, for their time and insights in preparing this article.
To learn more or get involved with DIF’s Trusted AI Agents work, visit the Trusted AI Agents working group page.
- Hardt, Ed. (2012). “The OAuth 2.0 Authorization Framework”. IETF. ↩︎
- Lab42AI (2025). “When OAuth Becomes a Weapon: AI Agents Authentication Crisis”. Hackernoon. ↩︎
- Simons, Alex (2025). “The Future of AI Agents - Why OAuth Must Evolve”. Microsoft Entra. ↩︎
- Feng, K. et al. (2025). “Levels of Autonomy for AI Agents (Working Paper)”. Arvix. ↩︎
- Anthropic (2024). “Introducing the Model Context Protocol”. Anthropic. ↩︎
- South, T. et al. (2025). “Authenticated Delegations and Authorized AI Agents”. Arvix. ↩︎
- Wang, Nancy (2025). “Closing the credential risk gap for AI agents using a browser”. 1Password. ↩︎
- South, T. et al. (2025). “Authenticated Delegations and Authorized AI Agents”. Arvix. ↩︎
- Alan Karp (2025). “Use Cases for Access Management”. Alanhkarp.com. ↩︎
- NANDA: The Internet of AI Agents. ↩︎
- Lemmer-Webber, C. et al. (2025). “Authorization Capability for Linked Data v.0.3.”. W3C. ↩︎
- SPIFFE Overview. ↩︎
- WIMSE IETF Working Group. “Workload Identity in Multi-System Environments”. GitHub. ↩︎





