
v1.1 of the 3 specifications includes one powerful new moving part
As CAWG activity picks up steam at DIF, there are a few details the rest of DIF and the broader community of decentralizers might want to be tracking:
- The specification includes a powerful new indirection called an Identity Aggregator, which designates an external authority to translate a long-lived identifier embedded in signed credentials (at time of publication) to one or more identifiers with local significance anywhere an asset is used (at time of republication or consumption).
- Industry-specific identifier schemes are being researched by a distinct task force within the group for prototyping and getting adoption in media verticals.
- Registering/organizing external metadata standards and DID interop are on-going discussions.
Wait, what Working Group is this?
If you're following from a distance, you have a vague sense that CAWG is a DIF working group doing something-something C2PA. If that distance is a long distance, you might know C2PA is a big-name, media-authenticity initiative with many mega-corporations signed on. The reality is actually more decentralized than meets the eye: CAWG is specifying open-world extension points that use Verifiable Credentials to let all kinds of claims and all kinds of actors embed metadata and rights declarations in C2PA documents, not just the big boys.
As the name would imply, "creators" is a capacious term which includes influencers, independents, rights-holders unions, creative agencies, freelancers, and even anonymous social media microcelebrities alike. The extension points and interoperability mechanisms this group is working on bring verifiability at various scales at once, and to various kinds of ecosystems and markets. The "Assertions" that these creators are inserting into signed C2PA manifests embedded in professional media assets are the open-world extension point that let C2PA manifests contain arbitrary metadata (treated in a separate specification being iterated by the group), arbitrary trust signals, and arbitrary attached credentials.
Enter the Aggregator
The Identity Claims Aggregator (often referred to as "aggregator" in the group) names a piece of software (which can be internal or external to an authoring tool) that tracks multiple identifiers enabling verifiable credentials (issued against them) to be inserted meaningfully. It also witnesses proofs of (and later attests to) control of many kinds of external identifiers, and generally organizes the chaos of the world's many overlapping identifier schemes and attestation formats. To the outside observer, this might seem a very complicated translation mechanism, but to the decentralized identity veteran, this is a familiar necessity. Every verifiable credential scheme eventually needs this kind of translator/aggregator role, if it is to be an open system or even if it is "only" going to federate across the tech stacks of multiple existing systems.
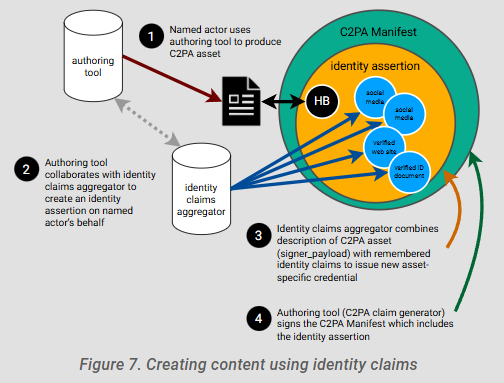
The conversation so far in the working group has been working its way from the general to the concrete: do aggregators only aggregate identifiers and information sources known at the time of authoring/inserting, or can an aggregator add on new attestations at a later time? Must aggregators limit themselves to public identifiers, or can they use an internal/aggregator-specific one? Can an aggregator host a live API for post-facto information to be passed out-of-band, like additional credentials or updated credentials? How tightly, if at all, should this group specify such an API, if so? These are the high-level questions being debated on the back-burner of CAWG meetings this summer.
The Aggregator-Indirection Question
Zooming in a little more, there are further questions being tackled. Aggregators model a great happy-path solution for embedding declarations and strong identifications into each asset, but what about the many unhappy paths? For example, what if a creator’s assertions are scattered across many identifiers and credential types, and embedding those assertions requires all kinds translations and metadata to be legible? What if identifiers change, or new assertions become relevant after publishing– can “placeholder” or indirection identifiers be used to query data sources that continue receiving assertions after publication? Can an indirection or service be used to display more or less assertions depending on audience, or changeable-over-time consent policies? Can assertions and identities be “self-custodied”? What is the “account recovery” story for these increasingly complex use-cases?
While adding the aggregator was the biggest change in v1.1, it will be a long while until the exact scope and limits of this role are decided. It may well be that some advanced features get postponed to a later stage in the roadmap, because of the sheer complexity they entail, but it will definitely be an ongoing topic simmering in the background whenever smaller debates come up.
Separate Work Stream: Industry-Specific Identifiers
In parallel, a subgroup is meeting separately to research and sanity-check the integration of major media-industry identifier schemes and metadata schemes, looking for interop corner-cases and relevant prior art.
Interested parties are encouraged to pop into the subgroup's github issues and meetings if they are working on (or just curious about, or experienced with) industry associations and media archiving best practices. The usual IP caveats apply: if joining a live call as a non-DIF member or commenting on github issues, refrain from going into concrete detail on anything "patentable" like implementation details or solutions.
Other Big Questions between V1.1 and v2.0
These advanced features of the aggregator aren’t the only big questions that we can expect to simmer and percolate across the next few "minor versions". Additionally, the interop issues around existing metadata standards (not just major W3C standards, but real-world ones from industry and library sciences) are potentially inexhaustible, as the group's Metadata specification gives scaffolding for inserting any structured metadata into assertions.
A slightly less vast but still very open-ended interoperability question is which DID methods to recommend or even require of all implementers, and how to manage or triage the remainder of the list of possible current (and future!) DID methods. Intersecting with the ongoing work of the DID Method Standardization Working Group, and older efforts like DID Traits to define equivalence or translatability between DID methods with similar architectures, semantics and guarantees, there is something of a simmering backlog-debate about which forms of DID make how much sense for the CAWG use-cases.
Of course, the evaluation of DID methods for these tiered-accreditation and decentralized reputation use-cases necessarily includes more than just technical analysis; legal and business readiness factor in as well, including competitiveness and market health/structure considerations to keep media authenticity from being a perk in closed ecosystems. Luckily, the new co-chair Scott Perry brings much experience and open lines of dialogue with multiple working groups at the Trust-over-IP Foundation which work on exactly these aspects of DID technology and business processes. In particular, agentic identity is a topic that ToIP generally, and Scott specifically, are bringing into the scope of the WG, so keep an eye out for issues and PRs along those lines in the coming months as well.