Report from PIDapalooza
[Originally published by Markus Sabadello on the DIF Medium account]
Some time last summer, our community around Self-Sovereign Identity (SSI) and DIDs made a fascinating discovery: PIDapalooza, a conference whose tag line is “open identifiers deserve their own festival”.
We were immediately puzzled and intrigued at the same time — how was it possible that there was an entire community dedicated to PIDs (persistent identifiers) that our community around DIDs (decentralized identifiers) has not heard of before? A community that was obviously working on very similar concepts but so far has had zero overlap with ours? So, three of us DID people (Pam Dingle, Kaliya Young, and myself) independently submitted proposals to present on DIDs at the PIDapalooza conference in Dublin. Kaliya’s talk titled “DIDs are PIDs” was chosen by the organizers, but for logistical reasons I ended up going there instead. And I’m happy I had this opportunity!


What a fun experience. I received a warm welcome, had some great conversations, and learned the following about the PID community:
- This community consists mostly of researchers from a wide variety of fields. They use different types of PIDs to identify objects that are of interest in their particular area, such as proteins, asteroids, neutrons, and many other things.
- In addition, they use PIDs to identify scientific publications such as books, journals, or reports.
- Finally, they also use PIDs to uniquely identify individuals such as researchers or employees.
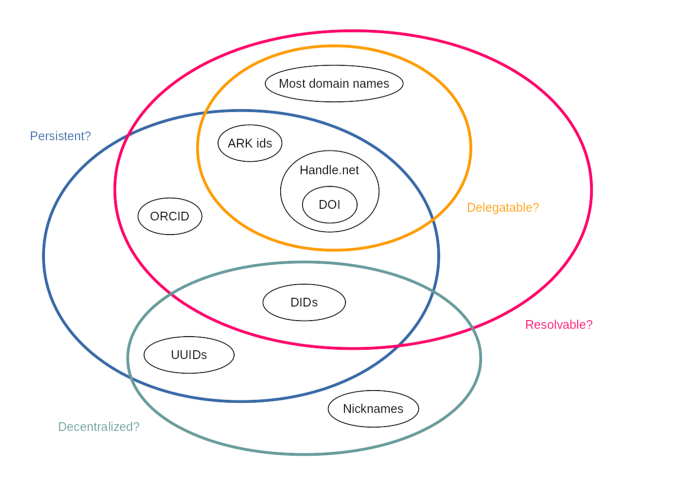
They have a quite mature set of technologies which they apply to the above use cases, including ORCID (PIDs for individuals), Handle.Net in conjunction with DOI (PIDs for publications), ARK IDs (PIDs for both digital and physical objects), and others. They also have various tools for registering and resolving these identifiers, e.g. Identifiers.org and N2T.
All of these PID systems are based on either DNS or other kinds of central or hierarchical registries. Some of them support various types of delegation. None of them are fully decentralized, and they would not qualify as “self-sovereign” the way we are designing DIDs. That’s okay! Different use cases require different technologies.
My conclusion was that DIDs are indeed PIDs, but due to their decentralized nature they are different from other kinds of PIDs that the PIDapalooza community has been using. I would describe the relationships as follows:
The most interesting conversation I had at the conference was on how to bridge identifier systems; for example, how could DIDs be used within existing PID infrastructure. One example is to add DID support to a PID meta-resolver such as the one at Identifiers.org. I reached out to the administrators of that resolver, and indeed, that tool can now resolve DIDs by delegating the did: prefix to DIF’s Universal Resolver:
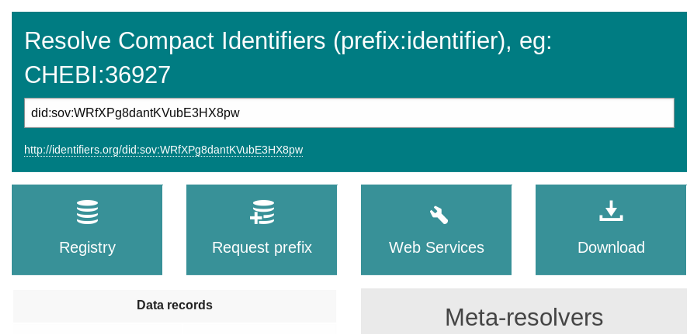
There are some drawbacks of this setup of course, especially a dependency on TWO centrally hosted third-party services (identifiers.org and uniresolver.io). Those of us working on DIDs would prefer resolving identifiers by “directly” reading from a DID’s decentralized target system. But conceptually, this is a first step to show that indeed DIDs are PIDs. I hope our two communities will be able to learn from each other more in the future.




