A crash-course in the complex world of variously-open software licensing
[This post was co-written by Kaliya Young and Juan Caballero]
The ostensibly binary distinction between “open” and “closed” software gets bandied about in many contexts, often in a dangerously simplified form, as though there were only two, mutually-exclusive options. It can also be extended to standards in an imprecise or oversimplified way. Sometimes people refer to groups like DIF “working on open-source standards,” but speaking precise, no such thing exists!
Only software code can be open-source, since after all, “source” is short for “source code” (pre-compiled software). Standards, whether open or not, are not code — instead, they are functional definitions and specifications that define and specify protocols that one application (or code base) uses to talk to another (or code base). Each standard can be understood as a benchmark for testing specific implementations, dividing existing and future codebases into those fully, partly, or non-compliant with its requirements.

Code, whether open-source or not, can implement or “build to” a pre-existing standard, which can be developed in a variously open or closed manner; there is no inherent link or dependency between the openness or rigor of the two processes. Similarly, a standard can be “written around” one or more existing implementations, in such a way that the existing code is definitively compliant with the resulting standard tailored to it. This latter operation is an important function in open-source communities, in that it invites future developers to make new code that will be interchangeable or interoperable with that precedent. Even if that pre-existing code is closed, the resulting standard can be of great use to open-source development, particularly if the process used to write it was also “open” and participated in by the designers and implementers of that closed-source precedent.
In this series of three brief explanatory posts, we’ll first explain open-source development as a process rather than defining it by its results. In the next post, we will explain the characteristics and optionalities of an “open process” for developing standards. Supporting these open standards is where the bulk of DIF’s efforts and resources are focused. Lastly, we will turn to how open source and open standards work together to create new business models and strategies with real-world consequences for cooperation, “coöpetition,” and healthy markets.
Source Code and Intellectual Property Law
At their lowest level, computers are just machines that exercise millions of structured computations every second. They take inputs, perform computation, and produce outputs.
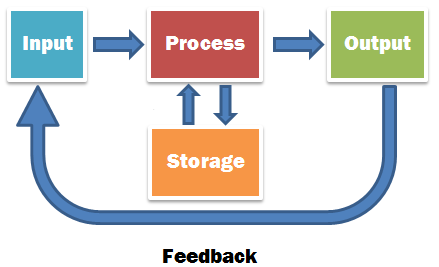
These computations can be combined into complex structures of data and decision-making called “programs” that interface with humans to make useful and meaningful outputs. At the lowest level, these computations still look like oceans of 1s and 0s to the untrained eye, but decades of refinement of operating systems, programming languages, scripting languages, and other abstractions make it easy for engineers to deal only with “source code” as a kind of human-readable abstraction at higher levels. This is “compiled” into more efficient, machine-readable “binaries” (ones and zeros) that can be deployed to standardized hardware in the real world where it is “run” (live software is often referred to as “runtime”).
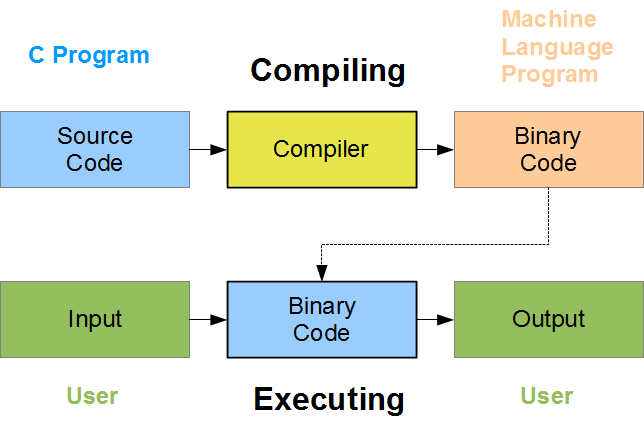
Because it is human-readable and because licenses apply to compiled binaries and functional software in specific jurisdictions, the software industry has largely applied practices analogous to academic “peer review” for sharing and critiquing core pieces of source code. This complicates the open/closed distinction further, since a closed-source project and a licensed binary might still offer key components up for review through github or other channels traditionally used for open development. Furthermore, the many gradients between complete “open” or “closed” software depends on the ownership and licensing of a given piece of software, which can evolve over time or differ in its enforceability across jurisdictions. Like all legal matters, mileage may vary and always consult a licensed expert!
A thumbnail history of licensing
There is a range of different licensing regimes for source code. Among open-source licenses, different functions can be enabled or facilitated independently of one another: external review, attribution, innovation, maintenance, and even revenue-sharing and other conditions on business practices.
Proprietary code bases are released under closed-source licenses, which are optimized for secrecy, exclusivity, and/or sale of the results through licensing-based revenue models. For decades, this was how Microsoft licensed not only its proprietary stand-alone software, but even the bulk of the Windows operating system. The licensing landscape is much more diverse today, but before the 1990s very little commercial software was developed in the open or had its source code published after the fact.
The culture of academia is one of sharing and publishing intellectual work for peers to see and review — open peer-review is as central in academic computer science as it is in the hard sciences. The internet was originally imagined, architected, prototyped, and built by academics, and tinkerers, primarily supported by military and government funding. These three cultures (the military, academia, and independent “hacker”/tinkerer types) formed the basis of internet culture. A fourth culture was added later when the general public’s access to the internet evolved into a massive commercial industry in the early 1990s.
For our purposes here, we can limit ourselves to the fairly direct link, sometimes biographical, between the anomalous, non-commercial origins of the internet and the development of the open-source movement within the software industry. One “origin myth” that exemplifies this link is the story of a young Richard Stallman, then working in an early Artificial Intelligence lab at the Massachusetts Institute of Technology, who wanted to customize some printer software for an expensive new printer shared across all the floors of a busy research building. To do so, he needed to get the source code from the manufacturer, which he had done to customize the previous “workhorse” printer in the same building.
The manufacturer of the new model, however, surprised Stallman by refusing to hand over the code on grounds of licensing and intellectual property rights. Stallman, to whom the motto “software wants to be free” is often misattributed, often credits the incident for his deeply-held belief that the end-users of software have a right to modify and participate in the software they use, whether they paid directly for it or benefited from the procurements of governments. To this day, the details and boundaries of this right are still being debated, not only in open-source requirements for government procurements, but also in “right to repair” laws that extend these rights into the domain of hardware and the physical (and 3D-printed) world.
Varying degrees of “Software Freedom”
Stallman went on to found the Free Software Foundation and play a pivotal role in the elaboration of an open-source (and “free open source”) movement. He also created the first GNU Public Licence (GPL), still a major and influential family of licenses. All versions of the GPL have within them some version of these 4 essential “freedoms”:
The freedom to run the program as you wish, for any purpose (“freedom 0”).
The freedom to study how the program works, and change it so it does your computing as you wish (“freedom 1”). Access to the source code is a precondition for this.
The freedom to redistribute copies so you can help others (“freedom 2”).
The freedom to distribute copies of your modified versions to others (“freedom 3”). By doing this, you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
Honoring these four freedoms textually and fully can make it very hard to sell software commercially for many reasons, salient among them that freely-available source code in a major language is trivial to compile into functioning binaries; commercial or “closed” software is generally sold as compiled binaries, keeping the source code secret.
Furthermore, many early open-source licenses like GPL explicitly forbid so-called “enclosure” of the code, i.e., incorporating pieces or subsets of the licensed code into a new, close-source product. Anti-enclosure licensing is often referred to as “copyleft” (because it prohibits future copyrighting!) or “viral licensing,” since it cannot be mixed and matched with other licensing without overriding more restrictive licensing. This severely limits commercial potential of “forks” or derived variants. The entire Linux family of operating systems are licensed this way, which keeps Linux development squarely in the camp of maximally-open development throughout.
Over the course of the 1980s and 1990s, the open-source movement grew and at some point the software industry could not afford to ignore it, even if directly participating with licenses like GPL was not feasible for most companies of any size. This period saw the first “compromise-licenses” and hybrid open/closed business-models evolve around them. Many of the licenses still popular today date to these early experiments. For instance, the license originally created for the University of California, Berkeley’s fork of Unix, and still known today as the Berkeley Software Development (BSD) license, is one such “commercially lenient” open-source licenses. These licenses allow developers to take code that was originally open, make significant changes to modified versions of it, and license or even sell those under more classically commercial licenses.
Similarly, more lenient variants of the Apache and MIT licenses date to this period as well. It is worth noting that Apache web servers were one of the first open-source pieces of software that replaced a dominant commercial product. Apache web server software reaching a dominant position in the previously closed-license, commercial niche was a watershed moment for open-source software.
Apache is often held up, alongside Linux, as an example of where open-source software optimizes for standardization and safety of mission-critical infrastructure, largely due to the thorough and ongoing auditing and maintenance enabled by its core components being completely open to review, testing, and improvement proposals. Conversely, however, some historians of software development point out that allowing enclosure to the degree that Apache licenses do can lead to simultaneous or “parallel” development of various (partially closed-source) forks to evolve in tandem according to various divergent business agendas. Over time, this can splinter development, wicking off talent, attention, and manpower into closed development and creating a major coordination problem for the open-source “parent” of the family tree. In the most severe cases, this can greatly diminish and forfeit the standardization and security gains that made sharing an open-source parent so desirable in the first place.
Today and Tomorrow
Today, cloud-based business models and Software-as-a-Service have revived and expanded the toolkit for closed-source development, and in turn breathed new life into the debate about how hybrid models could make open-source infrastructure sustainable by revenue shares from closed-source products that depend on it. Similarly, the so called “cloud loophole” in older GPL licenses, whereby software could be run but not “distributed,” was closed by the newer Affero GPL that applies to cloud environments.
Another interesting frontier in the evolving licensing landscape is being opened up in recent years by distributing computing and distributed ledgers. One key assumption of traditional licensing is that software runs on a finite set of distinct pieces of hardware, with ownership and liability that follow straightforwardly from there. Distributed computing, however, where computation work is spread out over a more diffuse and indeterminate numbers of computers, which might have limited or no insight into the “big picture” of the software they are running, muddy the waters even further than traditional cloud environment. On the radically open side of the spectrum, the distributed-computing ecosystem project HoloChain has innovated the Cryptographic Autonomy Licence to empower users (and the software running in their name) by protecting them with encryption.
New forms of “confidential computing” and encrypted, self-sovereign networking take this even further, making the boundaries of software and runtime environments similarly porous. Attempts at licensing for these new topographies have been controversial at times, but they are also an important precedent and context for work happening in the DIF, such as that of the Secure Data Storage working group.
There are even more radical experiments and movements happening in the open-licensing problem space, which would restrict usage not [only] according to commercial terms or enclosure, but according to non-monetary and non-licensing rubrics as well. For instance, the “ICE breaker” project has brought more attention to the movement to license software according to so-called “ethical licenses.” These restrict derivative use anywhere it can be proven to support of human rights violations, such as in military applications or for “predictive policing” and other use-cases that run afoul of international authorities on human rights and discrimination. The provisions or triggers for such licensing might be as hard to enforce as international human rights law (i.e., very hard), but it sends a signal that specifications and standards from other disciplines such as human rights law and ethical philosophy might someday find their place among the commercial and attribution clauses in open-source licenses.
Further reading
All code developed under the DIF umbrella is strictly open source, and while DIF accepts donations of previously-closed source code, it is expected that all ongoing iterations of them will take place in the open. The original vision for DIF as a project within the Joint Development Foundation was to host code development, and it has since expanded to include co-developed pre-standards specifications and other educational and non-technical materials as well. Take a spin through our github repositories if you’d like to see an overview of historical and ongoing projects.
In this quick overview, we have only scratched the surface, though, and we encourage anyone working in the open software space to educate themselves further. The Open Source Initiative holds the trademark on the phrase “open source” and maintains a very helpful list of licenses that it has decided are fully conformant with its principles. The list of approved licenses that they maintain is a great place to start if you are researching the licensing landscape, and they also hold events and offer a substantial offering of educational materials.
In our next installment, we’ll turn to Open Standards and the work of the Decentralized Identity Foundation.





