The community effort to bridge DID methods with a new data model
The world of digital identifiers (DIDs) and verifiable credentials (VCs) is evolving quickly, giving much cause for optimism. Standards are starting to connect and move towards functional interoperability, regulated by testable protocols. Most of this work is happening on the level of VCs. However, DIDs and their infrastructure are also starting to converge and mature as an extensible-yet-interoperable technology.
Adoption by markets, standards bodies and regulators is largely contingent upon provable security and provable interoperability, so these promising developments cannot come soon enough.
The Digital Identity Foundation (DIF) is very proud to be hosting one particular research and development project that could prove pivotal in this process. It is currently a work item of DIF’s Identifiers and Discovery Working Group. However, a charter for an autonomous working group will be available for review at #IIW31 this week (20–22 October 2020) to facilitate broader participation. The project is called KERI and it is a project that could only be developed in the open, for the public good and for the widest, quickest adoption.

But first, what is KERI?
KERI stands for Key Event Receipt Infrastructure. A “key event” is a discrete event in time that involves public/private keypairs, often called blockchain identities or cryptographic identities. These events can be generalized as inceptions (creations), rotations, and signing events: the three kinds of events for which KERI generates and handles receipts. In other words, key events are cryptographic events in the history of an identifier.
Importantly, everything else a decentralized identifier says, does, or refers to is not a key event. As KERI is deliberately laser-focused on key events only, we can call these other events non-KERI events. The real world consequences of a signature or rotation are out of scope and method-specific to boot. KERI is only interested in the most universal aspect of interactions between keys and cryptographic systems, i.e. the cryptography that allows drastically different DID systems to trust each other’s security guarantees.
“DID Methods exist to solve a trust issue. This does it in a different way.”
Charles Cunningham (Jolocom GmbH, Rust development lead for KERI)
Each key event produces a receipt containing only checkable signatures of key event information. Nothing more. Receipts are threaded into logs tracking the history of each identifier, which is similar to a traceable audit trail of hashes — useful for confirming but not for deducing the underlying key material. These threads are compiled into logs that are shared and replicated according to a consensus algorithm and a logic of trust thresholds that creates a fabric of shared history between nodes.
Is KERI a blockchain or a DLT? No. Does it replace blockchains? Also no.
The trust fabric created when KERI nodes share and propagate key material records might
sound redundant to the blockchains where all of today’s DID methods store their key material chronologically. To a degree, this is true: each log containing the history of one key is a “microledger,” like a blockchain with only one participant. Inception and rotation events in all of today’s DID methods are stored in a chronological distributed ledger which can be crawled to create a log of these key events by DID. So, why the redundancy? Why replicate a subset of the blockchain’s capabilities and features in a distinct blockchain-like infrastructure just for key material?
The answer is simple and manifold: blockchains enable many features outside the scope of KERI. These features bring with them complexity, diversity, scale costs, and trust issues. Within KERI’s scope, however, only some of a blockchain or distributed ledger technology’s (DLT’s) features are necessary. Total ordering and double-spend protection, for instance, are hallmarks of distributed ledgers, but hardly justify the added complexity here.
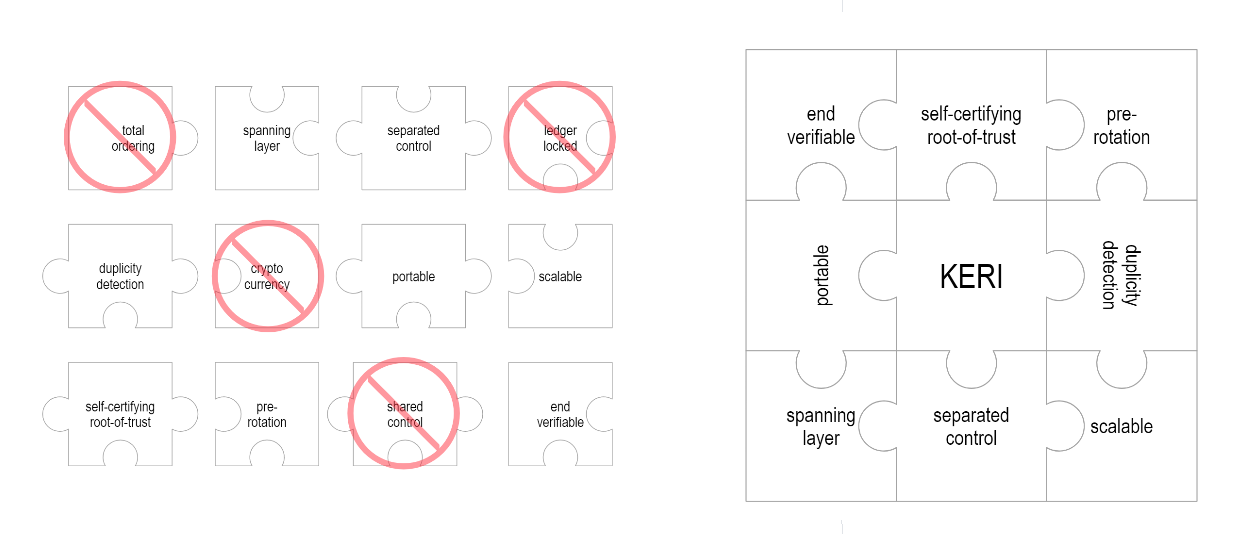
Working backwards from a short list of security features, KERI infrastructure can be a much more performant, minimalist distributed ledger system. It is still in the family tree of blockchain, DLTs and directed acyclic graphs (DAGs), but it is closer to a sidechain or a trans-blockchain interoperability mechanism. In use cases where all that is needed is a self-certifying, widely-portable identifier, KERI can stand alone as a lightweight DID method. In combination with a traditional DID Method, KERI can increase key management options and strengthen security guarantees by raising a red flag at the first discrepancy between the two parallel and redundant systems.
As a scaling mechanism, KERI can also take away some of the traffic and complexity from the underlying blockchain. In implementations where key management and state maintenance (record keeping about keys that rotate over time) are entrusted directly to the KERI mechanism, these functions can be operated much closer to the edge and replicate after a slight delay. This might be a totally acceptable trade-off of efficiency for latency in many use cases. For example, a roundtrip write-and-wait-for-finality transaction on a global blockchain makes no sense in a low-connectivity Internet of things (IoT) use case, where double-spend is a non-issue.
KERI is both an interoperability mechanism and a standardization incentive
More importantly for the DIF, however, is another major feature of KERI: it could become the foundation of massive interoperability and portability at the infrastructure layer. What’s more, if adopted by enough major players, it could even speed up the standardization process of DIDs themselves. By offering a minimum level of security guarantees shared across all participating methods, it would simplify the security review process for both individual DID methods and for interoperable DIDs as a whole.
By abstracting out the universal, minimal set of key functions, a KERI log that spans multiple ledgers or methods is just as verifiable as one that does not. This means that anywhere
self-certifying KERI identifiers are accepted, an identifier’s history can stretch back further than the existence of KERI. Plus, that history can include so-called “portability events”, where an identifier is deactivated on one ledger and re-activated on another. Method-specific features or records might still need to be exported and imported. The core proof of control function of a DID, however, would be universalized in a way that enabled massive portability.
This same universalizing effect of sharing a security vocabulary across all participating DID methods has the added benefit of being able to guarantee certain security features in any KERI-compliant system. Since KERI also lends itself to simple compliance tests, and since KERI logs give a benchmark against which to test method-specific and blockchain-specific security, this is a small leap for each DID method and a giant leap for standardization and security engineering.
KERI’s history: from whitepaper to community incubation
So far we have been highly technical in our explanation of the project. A careful reader, however, may already have caught the community commitment implicit in phrases such as “KERI-compliant” and “participating DID methods.” KERI is only useful if the major DID methods incorporate it, or if the set of participating DID methods becomes congruous over time with the set of major DID methods.
It is, in a nutshell, a community project of alignment as much as a technological innovation: an agreement on the security model for the common core functionality shared across all DID methods, allowing much variety and extensibility to be preserved by the participating DID methods. Decentralized identifiers have been very decentralized in their design and governance from the beginning, with a high degree of extensibility and flexibility within the fiefdom of each DID method and its governance. KERI has been gathering steam for over a year as a countervailing force, potentially making all DIDs function in an end-verifiable and thus universal way.
“Investing in KERI is investing in interoperability, standardization, and cross-community security guarantees.”
Dr. Sam Smith, author of the KERI whitepaper and project lead
In large part, the roots of KERI lie in debates within the World Wide Web Consortium’s (W3C’s) Decentralized Identifier Working Group. For years it has been discussing the “shalls” and “mays” that define a W3C-compliant DID method (and thus a DID system). In practical terms, this process specifies what each DID method can and must assume about other DID methods for such a decentralized and open system to make appropriate security guarantees.
KERI’s creator and the author of its whitepaper is Samuel M Smith PhD., a pioneering technologist in multiple fields, including automated reasoning, distributed systems, autonomous vehicles and blockchain protocol design. Dr. Smith has been refining and experimenting with such a cross-method mechanism since 2019, presenting at every meeting of the biannual Internet Identity Workshop. First came some core principles and requirements of a key infrastructure at IIW28, then at IIW29 a series of sessions about different aspects of a hypothetical system of witnesses that could replicate logs. For IIW30, Dr Smith brought more concrete sessions on finer points and even the roadmapping session that became the DIF working group. Along the way, he has iterated an ever-growing whitepaper describing and explaining all of this.
Now, however, Dr Smith has moved the project into the DIF under the auspices of its Identifiers and Discovery Working Group where he sits as co-chair. Asked about the decision, Dr Smith said, “DIF was a natural choice because I wanted the work to happen quickly but in the open, with participation from the greatest number of companies and innovators across various communities.”
KERI’s contributors: join us!
Foremost among DIF contributors is, of course, Dr Smith, who brings to his KERI design work more than a decade of engineering experience with scale and high-performance systems. Much of this work, focusing largely on AI and streaming/scaling projects, was done through his Python-centric consulting company Prosapien.com. He has also worked with Consensys, contributing to the Seed Quest project among others, soon to be donated to DIF.
Berlin-based Jolocom GmbH has been a major interlocutor in the early development of KERI, since before the creation of the working group at DIF. Jolocom’s Charles Cunningham is the working group’s lead Rust developer, who has written a highly interesting post about mental models of How KERI tackles the problem of trust from a developer’s point of view for the Jolocom logbook.
Representing Spherity GmbH are the working group’s lead JavaScript developer and note-taker. Spherity’s founder, Carsten Stöcker, has written a detailed piece for his company’s blog which called KERI “a more performant ledger for trusted identities.”
The Human Colossus Foundation, a Swiss-based non-profit, has been co-developing on the Rust side as well, working in parallel and providing input on the design considerations. The Human Colossus Foundation has also put substantial energy into promoting and socializing KERI in the Trust-over-IP Foundation, the MyData community and in the Sovrin community, including featuring an hour-long KERI session prominently in a half-day mini-conference it organized.
At IIW31, the KERI developers will be demonstrating their initial work to date while there is still the opportunity to get involved and determine the course of KERI as the project moves from direct mode (two-party) to witness mode (multi-party, distributed consensus). Many sessions are planned for IIW, ranging from introductions to technical discussions to use-case and requirements gathering for KERI-based ideas. Additionally there will be a live demo of the working direct-mode prototype.
Introductory reading and video materials are collected at the main DIF repository, but even if you don’t watch them in advance (or fully understand them if you do), there are many ways to get involved and make this community project stronger and more diverse.





